本文共 3473 字,大约阅读时间需要 11 分钟。
今天想给大家分享一下OPPO大数据平台规模极速增长历程中我们所做的一些工作,包括我们之前遇到的一些坑和收获的心得。
之前已经提到过OPPO的互联网发展是非常快的,对应到我们数据的规模和平台的规模在过去两三年也是在极速增长,那么我们怎么应对这些挑战呢?

我们在内部有一个口号就是要打造稳定、高效、安全的数据平台,上面这张照片是整个数据中心在公司的一个门面。这六个字说起来简单,但是在实际运营过程中碰到了许多坑,今天给大家分享一下如何面对这个挑战。
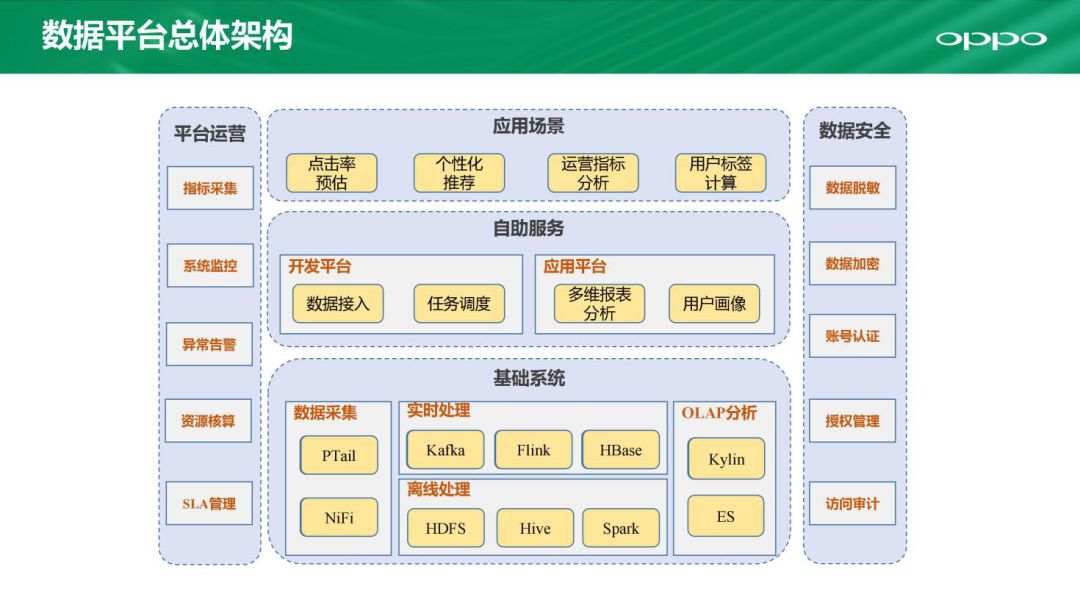
首先给大家介绍一下数据平台的一个总体架构,这里列出了主要的部分,我们把整个平台架构分成了三个层次。
首先是最底层,这是一个基础的系统。我们会用到Hadoop生态中的一些组件,包括一些实时的处理和离线的处理,还有数据的采集以及OLAP分析。这些组件目前主要是应用的开源组件,也有一部分是自研的定制化系统。
在这些基础系统之上,我们开发了很多自主的服务。面向开发者的平台包括数据接入和任务调度,面向应用平台的主要是服务我们内部的运营人员和产品人员,我们要帮助他们去做一些多维分析、报表分析还有用户画像等等应用。
在最上层就是数据的一些应用,一些点击预估和优化推荐、个性化推荐、运营指标分析、用户标签计算等都是基于这里来做的。
然后我们看一下架构的左右两边。左边是一些平台运营部分,用来支撑平台的运营;右边是数据安全的部分,用来保证我们的数据隐私性和安全性。
今天因为时间所限,我主要介绍一下平台的运营和自主的服务研发部分。
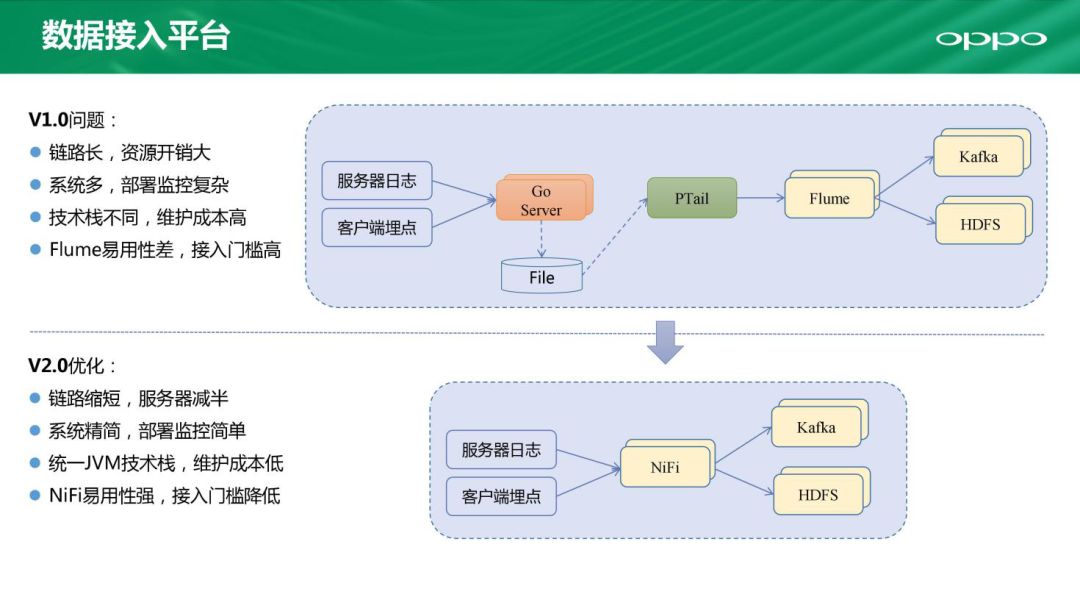
刚刚提到了我们整个平台的两个基本服务,其中一个是数据接入。我们接入的平台也经过了一次版本的演进,在1.0时代我们的数据来源主要是两部分:一个是服务器日志,另一个是我们手机上的客户端埋点。这些埋点我们统一通过一个Go语言开发的HTTP Server落到一个本地的文件,再通过一个Python开发的类似Tail的工具,把这些实时滚动的内容集中到Flume集群,然后再转到Kafka集群做实时计算和HDFS做离线的处理。这个架构支撑了我们前期的一些工作,但是也有很大的瓶颈:涉及的系统多、链路长、技术栈多、协调性不够好、维护成本高。
去年时候我们升级了2.0版本。首先的改进是缩短链路,这样可以省下一半的服务器。技术栈统一使用JVM,还使用了一个比较新的开源组件NiFi,NiFi是一个Apache的顶级项目。我们通过这些组件对整个架构做了精简。
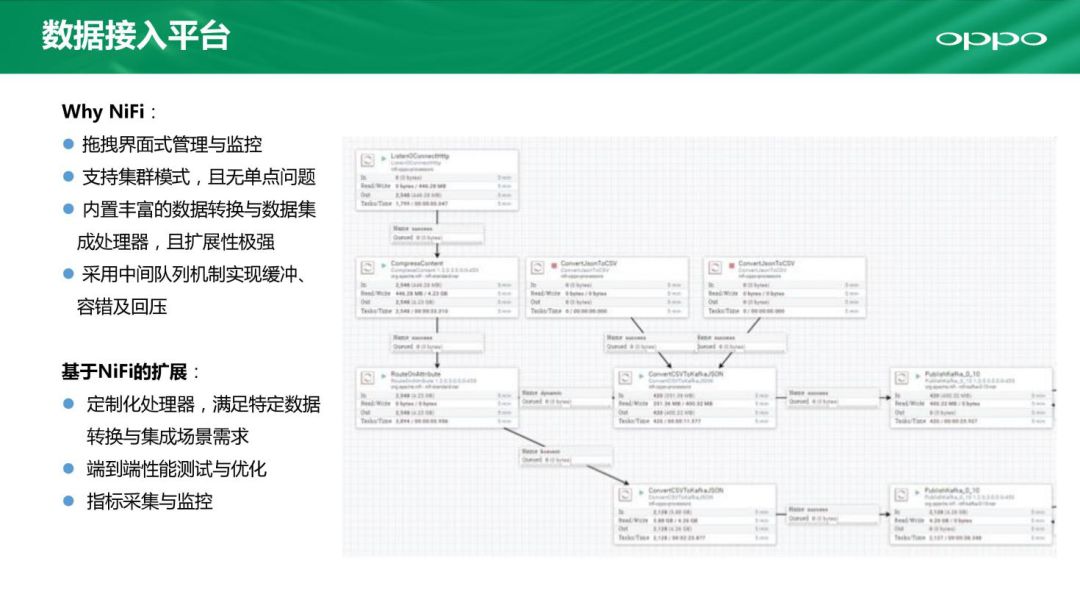
那我们为什么要用NiFi的系统来替代Flume呢?第一点也是最大的优势是NiFi是一个可视化界面,而flume都是一些配置文件。上图中每一个框都是NiFi的一个环节,可以把它们抽象成一个个处理器。处理器和处理器之间有数据的流转,同时支持集群的模式,把数据处理好以后它可以自动分配到集群上,去做数据的接入。再有一点是NiFi可以支持丰富的数据转换(包括格式转换,加解密操作等),对数据落在Kafka和HDFS上提供了很好的支持。NiFi每个处理器和处理器之间都有一个消息队列,每个队列可以实现一个缓冲来保持架构稳定。我们基于NiFi进行了很多的扩展开发来满足定制化数据转换需求,同时实现端到端的性能测试和优化以及指标采集监控。

第二个就是任务调度平台,也是从1.0进化到了2.0版本。1.0是一套自研的Shell脚本,在到达上千个任务的时候及时升级到了2.0版本的OFlow。

那么新版本的任务调度平台优势是什么呢?我们总结了有三个优势。
一、可视化界面。新的平台跟NiFi一样是一个可视化界面,每个任务之间的依赖可以进行可视化管理。
二、任务树。通过任务树可以方便查看到任务的历史执行情况、运行时间状态等。

三、甘特图。整个任务做成一个甘特图,通过任务链条和基于时间的执行情况,方便诊断问题。

其次我们基于AirFlow做了下面这些改进:BUG修复、细粒度权限控制、运营时发现的任务执行同比监控。通过上图我们可以很清楚看到是在哪个阶段出现了问题,看到这个阶段对比历史有延后。
我们的运营数据平台也会面临很多有困境,比如Hadoop系统非常杂、监控指标过多、诊断成本高等。

这个冰山图大家都见过,我们从上往下看,上面是大数据生态、抽象成一个平台画像的概念,类比于用户画像。我们把平台画像抽象成三个方面:数据、资源、任务。下面我们从这三个角度看剖析我们在平台画像上做了哪些工作。
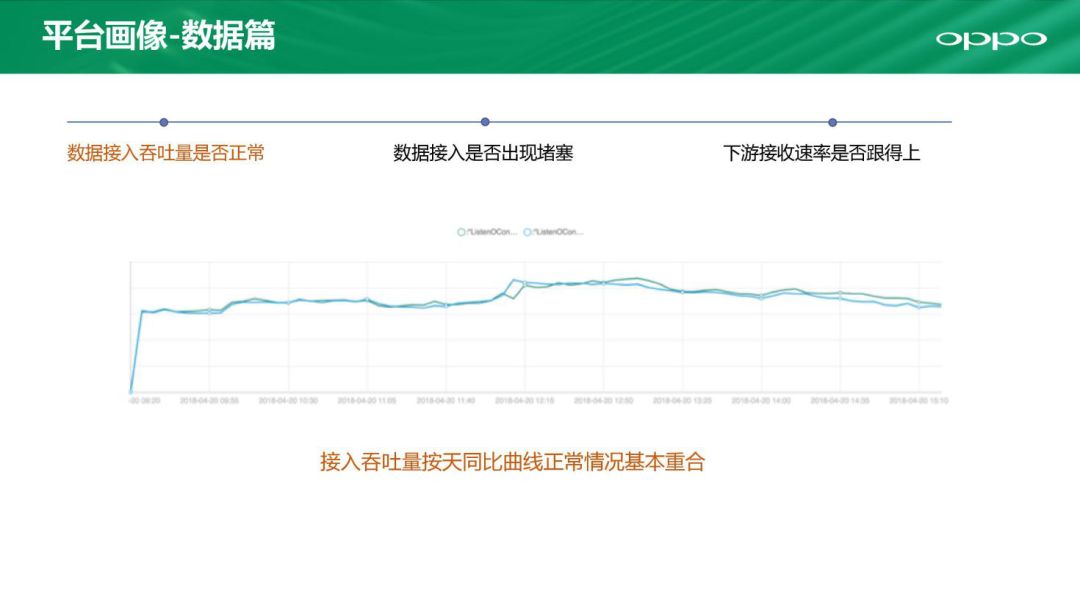
首先来看看数据。数据这一块怎么看是否满足业务需求呢?数据接入吞吐量有一个监控曲线,可以跟历史曲线对比。如果哪一天相差比较大,那就需要我们进行紧急介入处理。
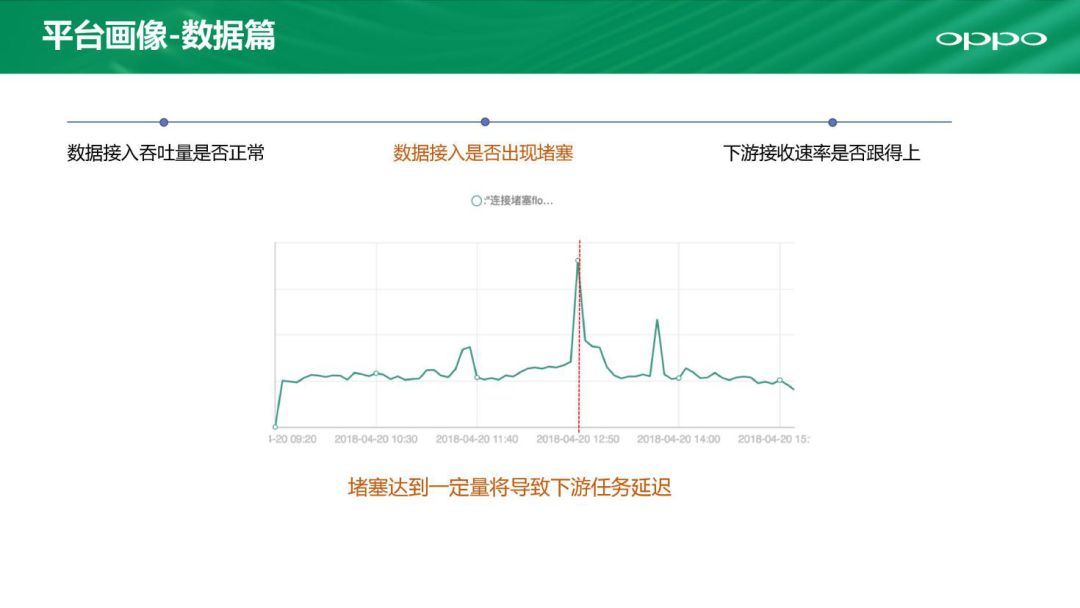
然后是监测数据接入是否出现堵塞,如果像图上出现了一条红线说明数据接入遇到了堵塞,需要做紧急处理。
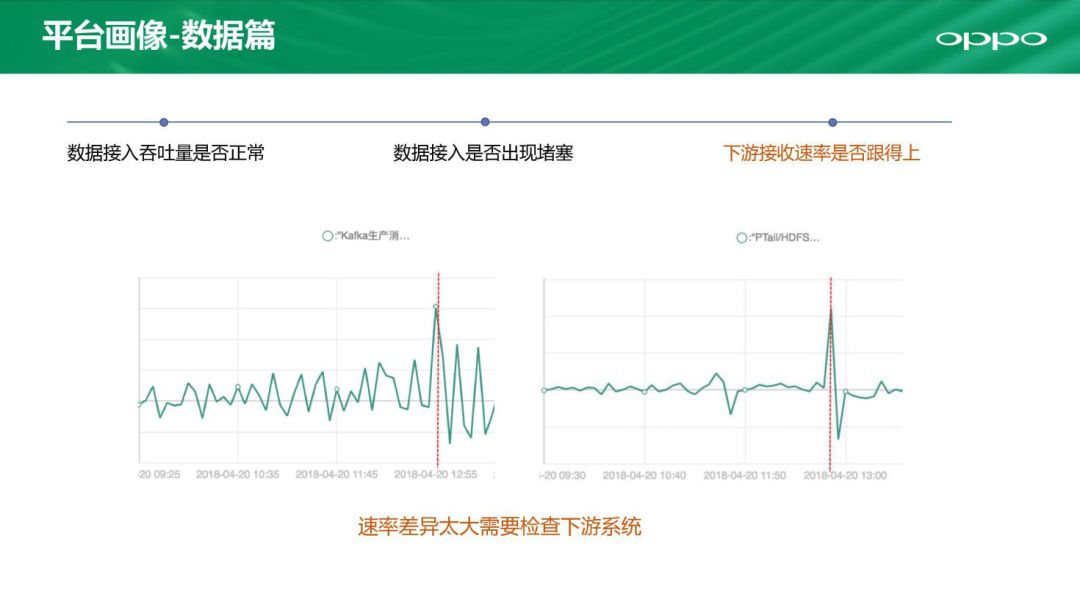
再有我们还需要考虑跟下游系统有衔接的问题。如果下游接收速率跟不上也会产生影响,这里可以检测是否跟得上。这是从数据的三个角度来看的。
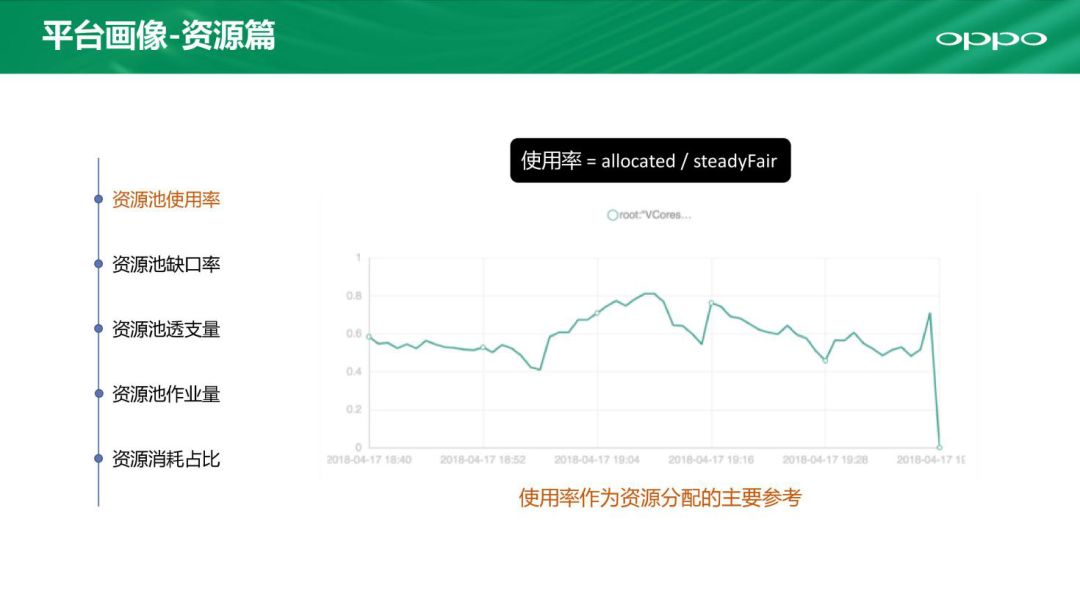
从资源方面我们也有5个角度去看。第一个就是资源池的使用率,这是一个最简单的指标,当然资源池使用率指标也可以用于参考不同业务的资源分配情况。
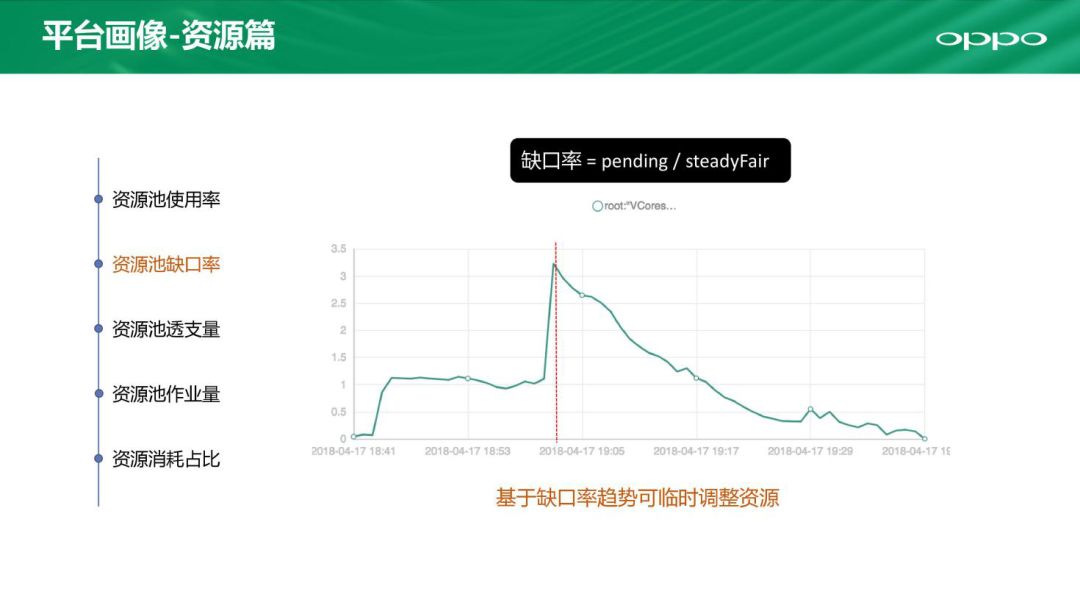
再一个也是很重要的指标叫资源池缺口率。若是缺口率很高,说明资源严重吃紧,需要紧急调配资源进行介入。
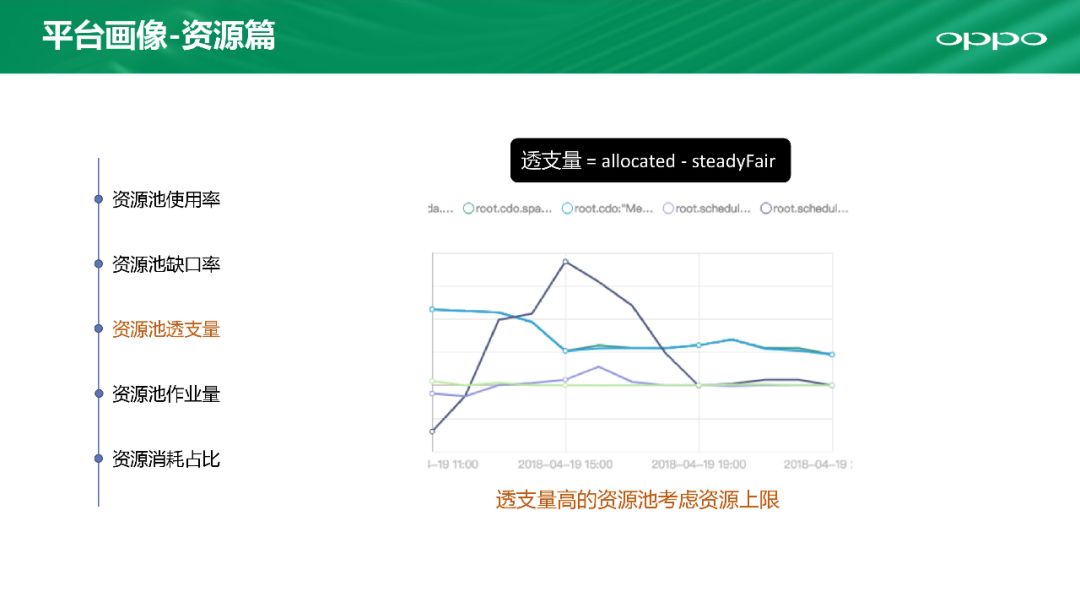
第三个叫做资源池透支量。为了保证各个业务公平高效的使用资源,我们允许透支资源,毕竟每个业务的高峰期不是一样的。但是如果透支量达到一定程度时,就要进行介入防止风险。
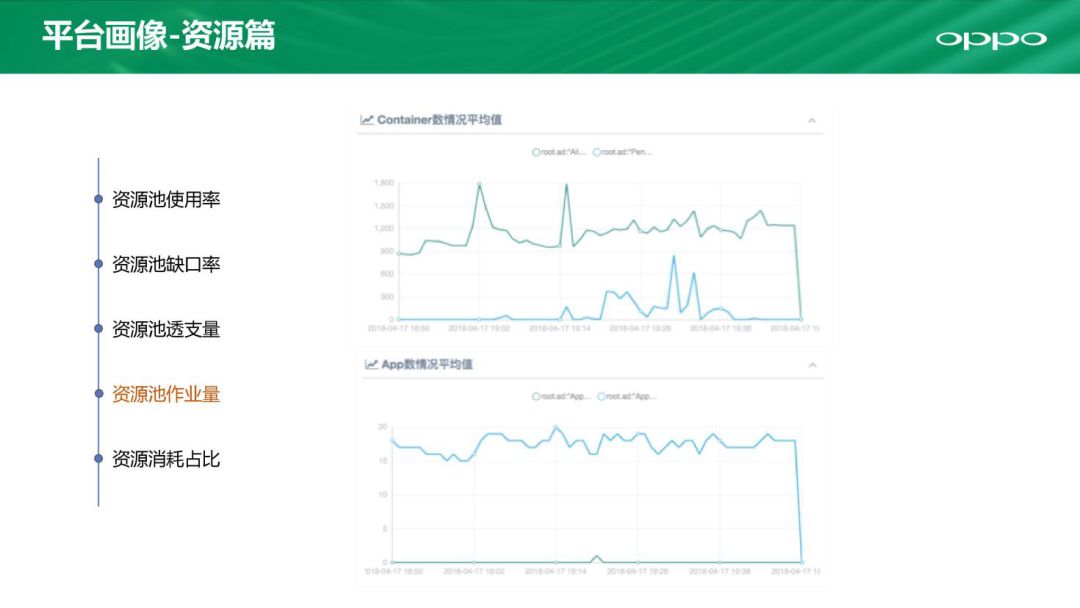
第四个是资源池作业量。通过密切的监控,我们可以看到Container数和App数情况平均值。
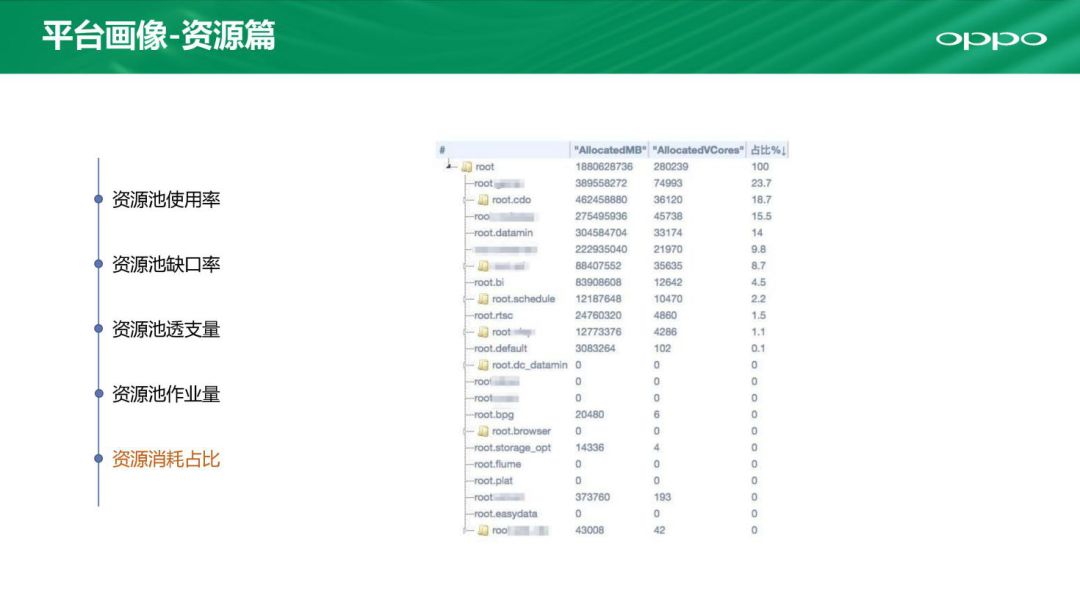
第五个是资源消耗占比,这是一个汇总的展示。
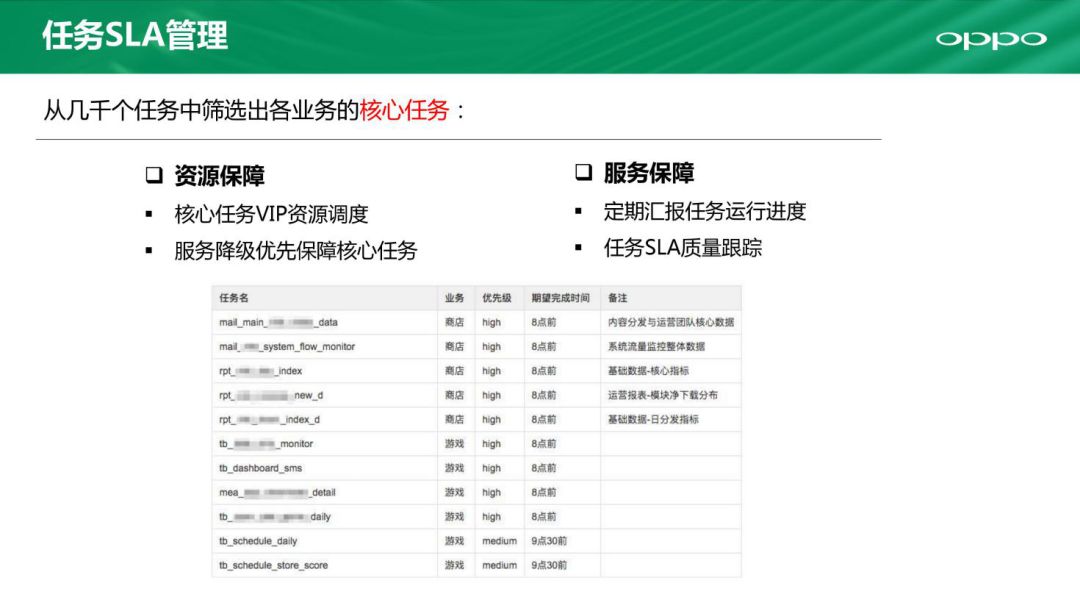
现在说一下任务SLA管理,我们整个数据平台上有几千个任务,其中一项重要的工作就是梳理核心业务。我们去跟不同业务去聊,比如有些数据需要每天上报给高层领导,那么就把这些认为是核心任务,优先处理。
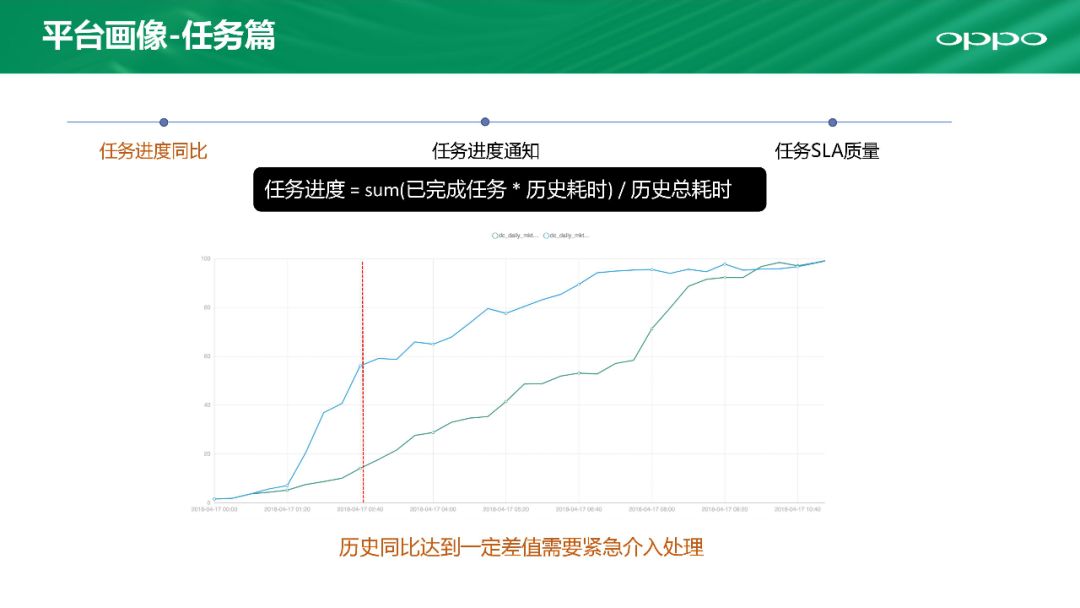
我们会根据核心业务要做一些平台画像,从三个角度去看。
第一个是任务进度。有一些任务有很多前置的依赖任务,比如我们有一个任务有20多个前置任务,如果不做任务监控,延迟会越来越大。上面这个图可以显示这个任务历史上进度的情况,上方曲线是历史进度、下方曲线是今天的进度,可以看到此时已大大落后历史进度,这就已经很危险了,必须紧急介入处理优先保障服务。那这个任务进度怎么计算呢?我们有一个公式:任务进度=sum(已完成任务*历史耗时)/历史总耗时。
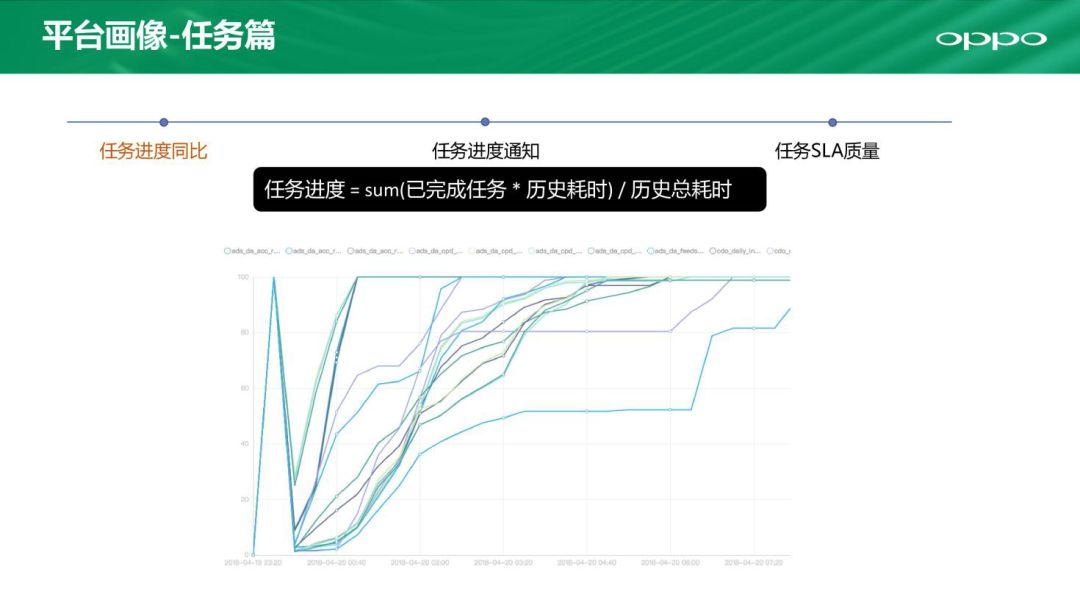
这是多任务的一张展示进度图,横坐标是时间。
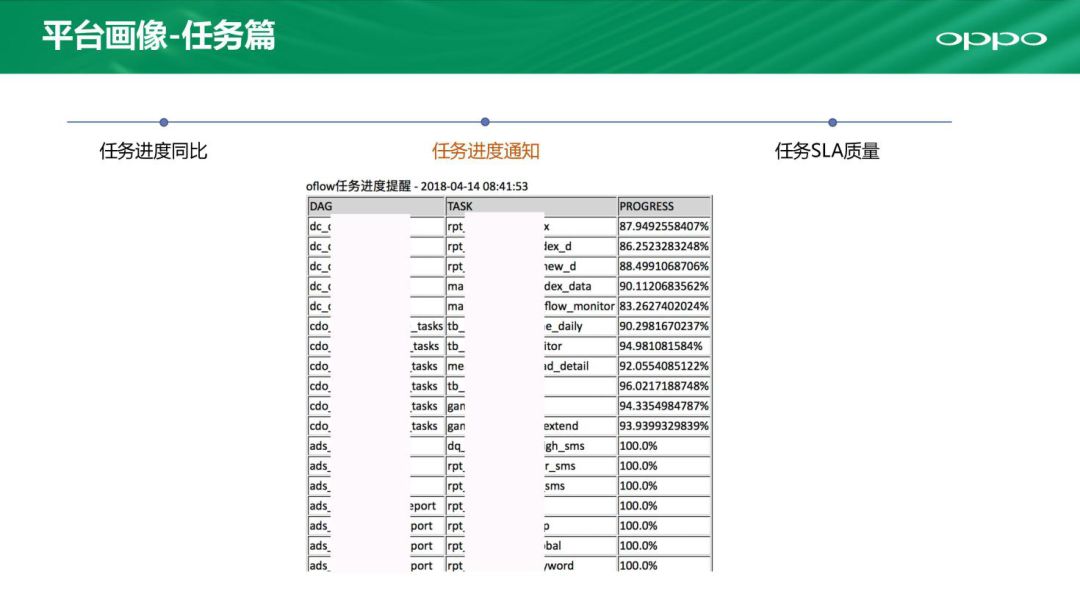
这是任务进度的通知部分。可以通过邮件电话告知,将列表定期发出来。

这里看到的是任务SLA质量,可以抽象成两个指标:准点率和准点度。其中准点度是负数代表任务提前完成。

当然平台的不稳定也有内部因素,比如人员数量的改变,用户使用不规范等。

我们不应该被动等待出现问题,而是应该应该主动出击制定规则。我们有两个方法来化被动为主动,分别是产品约束和工具检测。

我们从去年开始使用的一个工具Dr.Elephant,内部管它叫大象医生。举个例子,我们可以用它检测每个map的大小,如果误差太多就会将它暴露出来,方便我们去进行处理。

大象医生也可以对资源的使用情况进行检测,比如一个任务申请6G内存,但实际只使用了1G,都可以用它把问题暴露出来及时去解决。

前面所说的都是服务开发人员的,现在讲一讲如何服务运营人员。通过上图对比我们可以看到Tableau是商业收费软件并且只有桌面版、Hue的系统也不够稳定,所以我们自研了一套针对运营人员的自助分析平台。
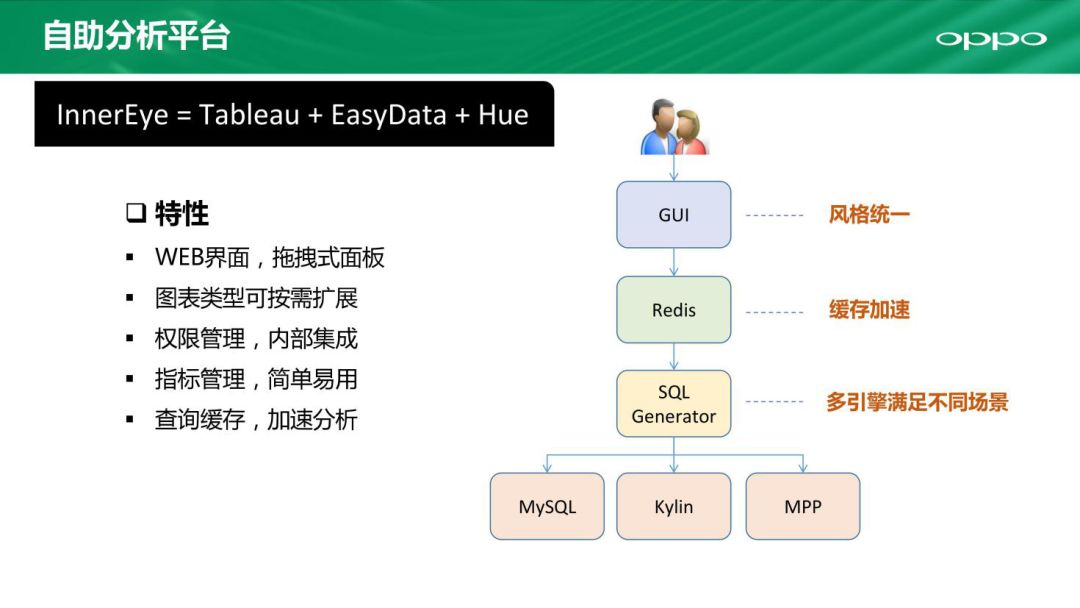
自研的自助分析平台叫做InnerEye,具有统一的用户体验,包括GUI风格统一,Redis缓存加速,涵盖了不同引擎以满足不同分析场景。
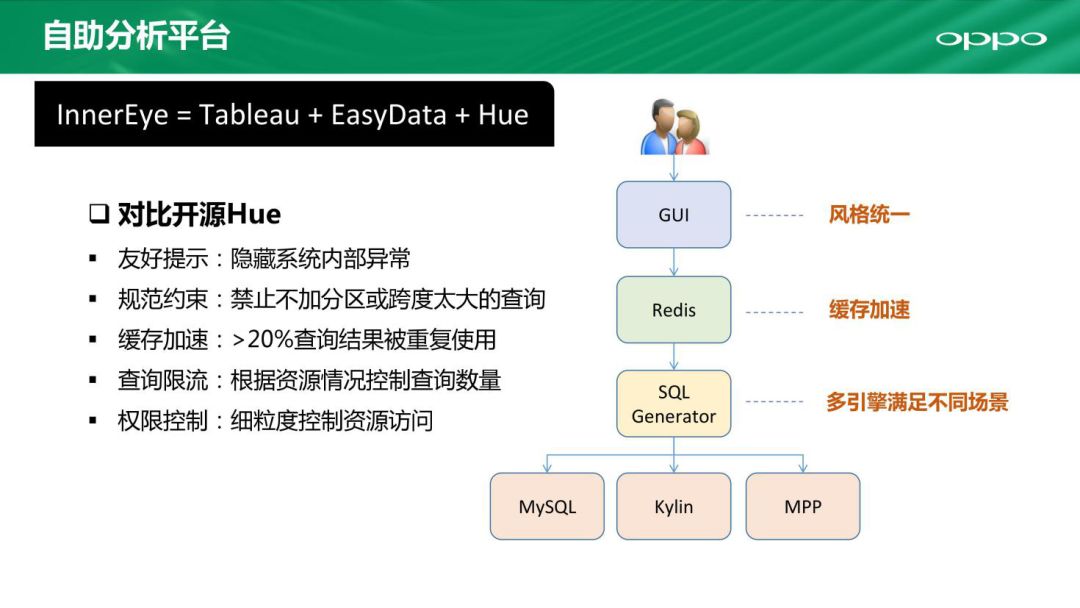
Hue的缺点很明显,比如如果出现了异常就会直接抛出,对业务人员很不友好,而InnerEye就有有好的提示以及规范约束,还有缓存加速特性,体验更好、资源消耗更少,还能做到查询限流及权限控制。
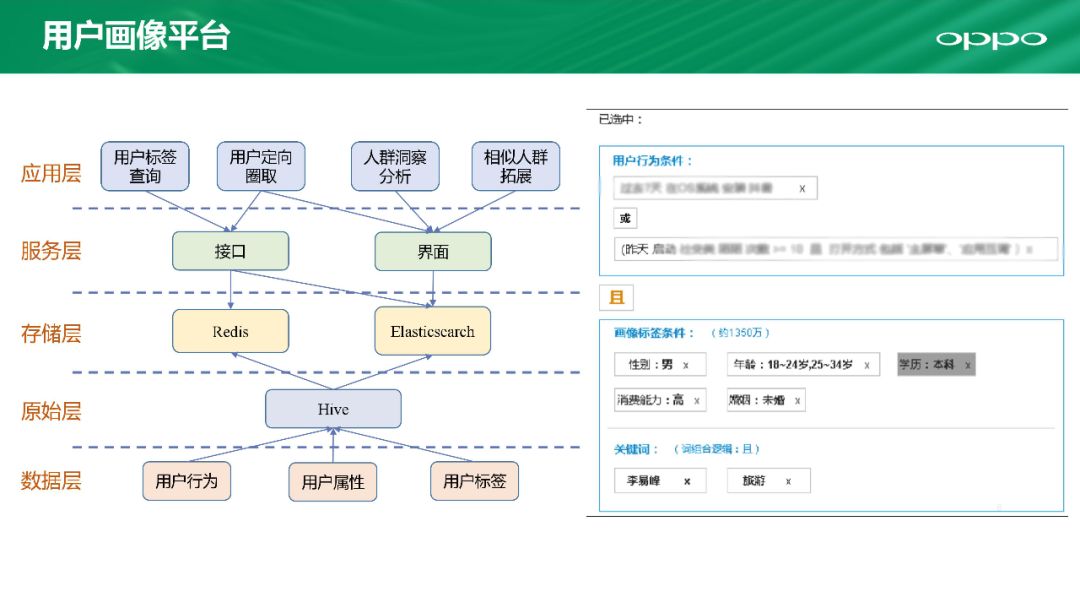
我们打造了一个如上图的平台。应用层下方有一个 服务层,包含接口和界面。接口使用Redis进行缓存,可以做到10ms以下延迟。而ES可以做到一个小时内将所有标签进行更新。原始数据通过Hive传入Redis和ES。
上图右半部分我们看到有一个统一的面板,可以选择不同维度筛选进行结果展示,还可以做到给定一组关键词进行关联,这些都可以通过平台完成。

至此我们打造出了一个稳定、高效、安全的数据平台。刚刚安全部分没有讲到,其实我们在这里也做了大量的工作来保证数据的安全性,比如统一的账户管理和授权,以及审计记录的审查等等。
本文来自张俊在 DataFun 社区的演讲,由 DataFun 编辑整理。
转载地址:http://elevx.baihongyu.com/